Profiling
As the first step of the parallelization, we need to figure out which part of DeepFlow takes most of the execution time. Below is our profiling result. You can reproduce our profiling result by setting PG flag to TRUE in our CMakeLists.txt.
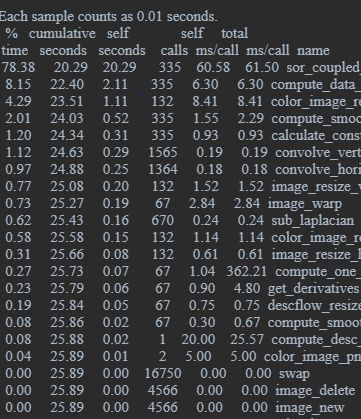
More than 78% of the time is spent on a function called sor_coupled. That's where Successive Over Relaxation (SOR) method is used to solve the linear system. So we will parallelize this linear solver.
Algorithm Change
Jacobi, SOR and Red-Black SOR are all optimization algorithms solving linear systems and all of them are iterative methods.
SOR (original implementation)
The original DeepFlow implementation is based on SOR method. Below is the equation for SOR to solve Ax=b.
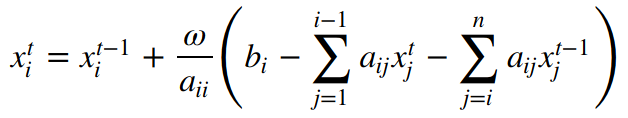
where t stands for the current step and t-1 stands for the last step. As we can see, the right hand side of the above equation has xt terms, which means there're dependencies inside each step. Therefore, the SOR algorithm is not parallelizable and we need to change the algorithm.
Here is the code for SOR in case you want to know more details.
Jacobi (parallelizable implementation)
We first came up with Jacobi. The equation for Jacobi is shown below.
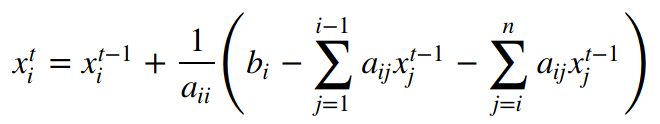
As we can see, all xt terms at right hand side are eliminated and thus there's no dependencies inside each step. Based on the equation, it's also simple to change the original algorithm from SOR to Jacobi at the high level, just replace ω with 1 and all xt terms with xt-1.
Here is the code for Jacobi in case you want to know more details. We also implemented the OpenMP and OpenACC parallelization for Jacobi.
Red-Black SOR (RBSOR) (Advanced Feature): parallelizable with better convergence
Red-Black SOR (RBSOR) is similar to SOR, but in each iteration we only update 'odd' or 'even' elements, thus when we update the 'odd'('even') parts 'even'('odd') parts are fixed. In this way we can prevent data dependency within each iteration. RBSOR has slightly slower convergence than SOR but in practice they are very close. Both RBSOR and SOR converge faster than Jacobi.
The implementation of RBSOR is more involved so we list it as an advanced feature.
Here is the code for RBSOR in case you want to know more details. We also implemented the OpenMP and OpenACC parallelization for RBSOR.
Comparison
Below is the visualization of the three algorithms (serial version). We want to update the 3x3 grid until converge (become light yellow). In each step, we update one element in the matrix. In Jacobi, the values are updated based on previous values; but SOR uses newer values whenever possible, while RBSOR update half of the board and alternates. It is also obvious that SOR and RBSOR converges faster than Jacobi.
| Jacobi (Serial) | SOR (Serial) | RBSOR (Serial) |
|---|---|---|

|

|

|
As we explained there is serial data dependency in SOR, but not in Jacobi or RBSOR. Theoretically within each step, each cell can be processed independently. Below is the visualization of the parallelized Jacobi and RBSOR, which is how our OpenMP and OpenACC parallelization works. Note: to make the comparison fair, you should compare Jacobi at step X with RBSOR at step 2X (the data processed by RBSOR in each step is halved) and in our implementation, we also doubled the steps for RBSOR.
| Jacobi (Parallel) | RedBlack SOR (Parallel) |
|---|---|

|

|
Empirical Experiments on Convergence and Quality
We generate the flow for gun smoke using original SOR implementation, Jacobi implementation and RBSOR implementation. Below is the visualization for the resulting flow (left: SOR, middle: Jacobi, right: RBSOR)
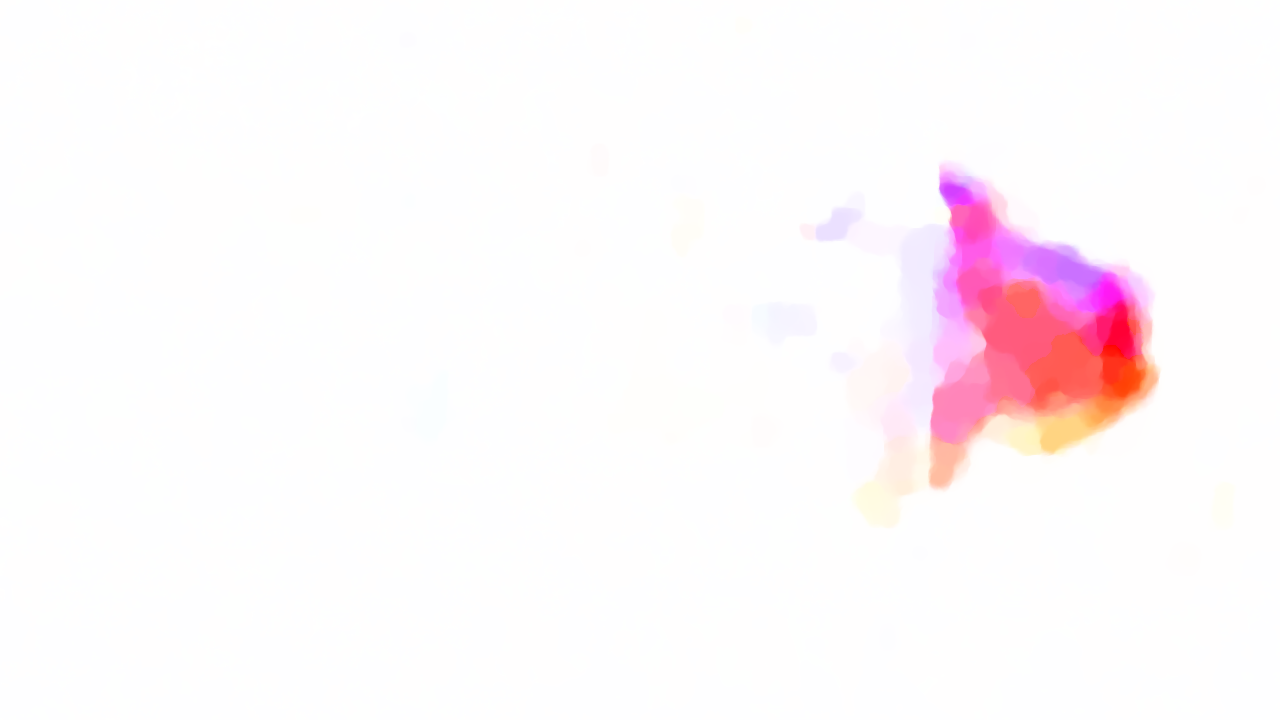
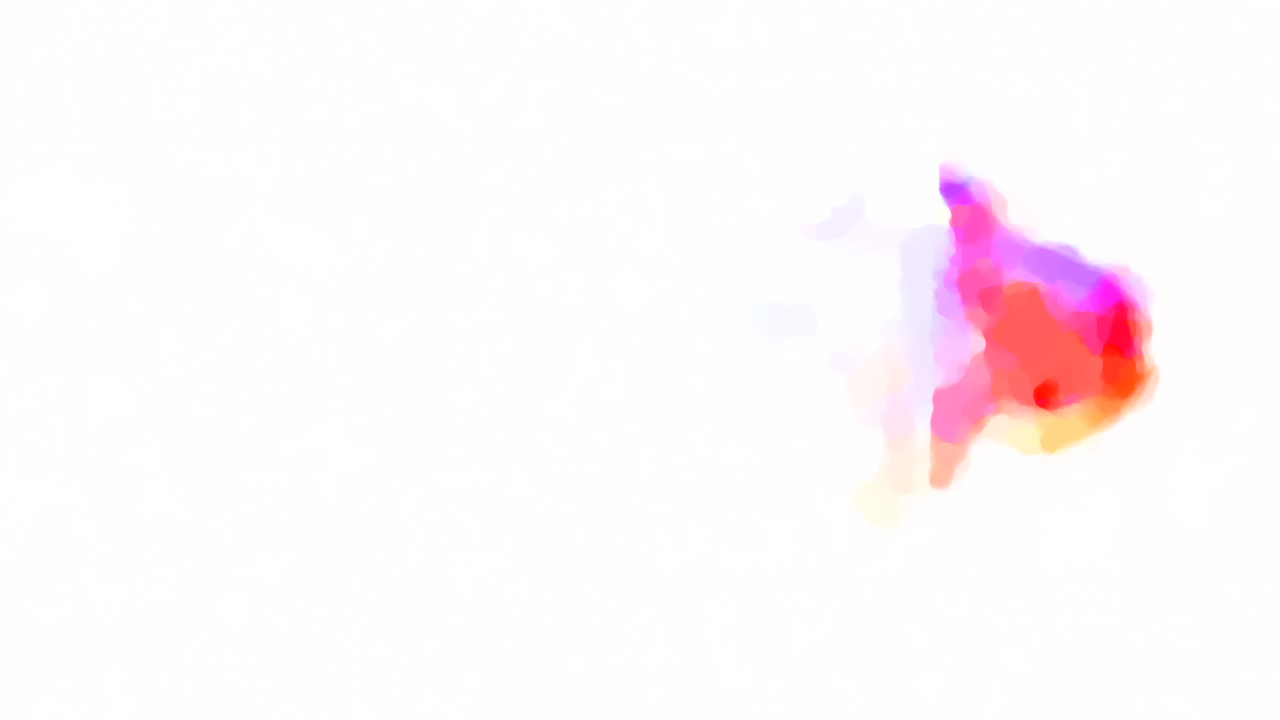
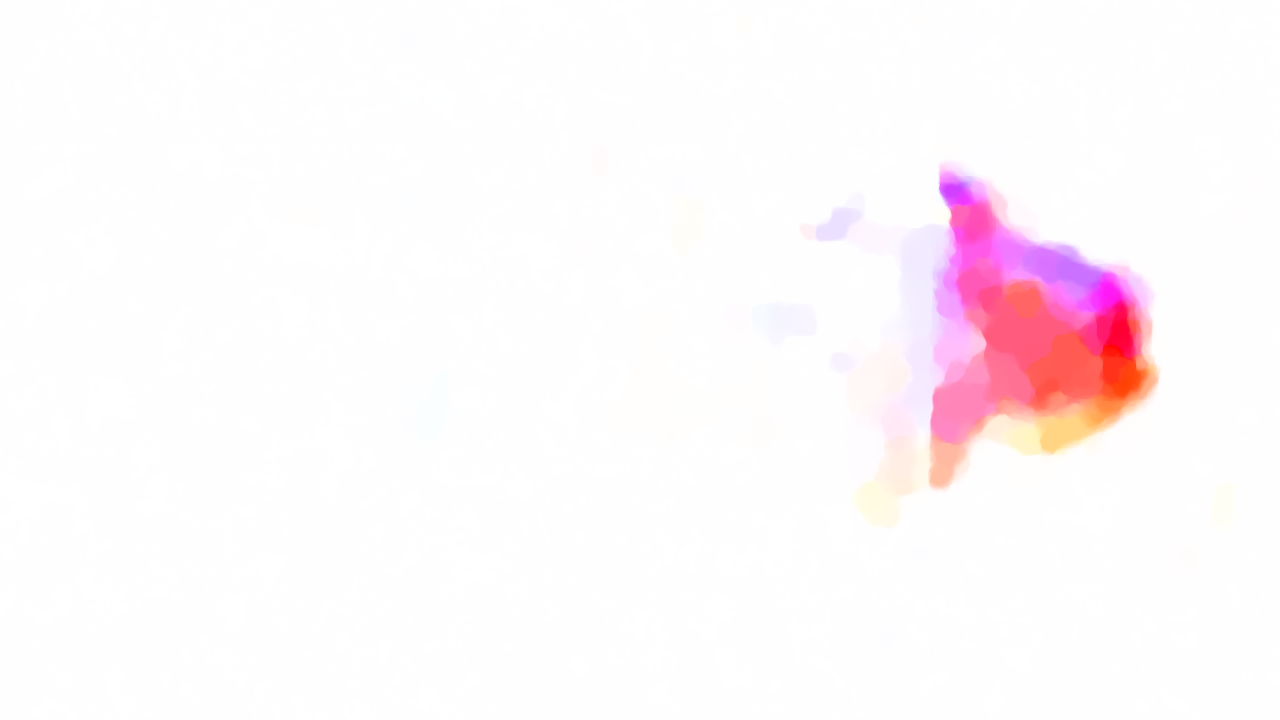
It's not easy to see their differences, though if you are careful enough, you can find the RBSOR and SOR results are visually same while Jacobi result is somehow different. To make the differences visible, we generate the diff-picture for both Jacobi (left) and RBSOR (right) with original SOR (black means same, otherwise, the values are different on that pixel) below. In order to make the differences visible, we multiplied the difference by 5.


Since our goal is that the parallelized output should be as similar as that of the original SOR output, From the diff-picture, we can conclude RBSOR is significantly better than Jacobi.
Parallelization Design
As analyzed in the last section, we'll use serial RBSOR as the base algorithm and try to parallelize it. We can also parallelize at the task level (i.e. for a video, assign the calculations of flows for different pairs of frames to different nodes). We think the problem and our parallelizations have the following characteristics.
- Type of applications: compute-intensive (and also data-intensive if applied to videos). This is because the linear system solver is compute-intensive and if DeepFlow is applied to videos, we will have to calculate flows for each pair of frames (48 pairs for two-way flows for 1-second 25fps video) and it's data-intensive.
- Levels of parallelism: Loop level (and also task level if applied to videos). The RBSOR is an iterative method. We parallelize the loops inside the outer loop. For videos, flow calculation for each pair can be parallelized and it's at the task level.
- Types of parallelism: Function parallelism (and also data parallelism if applied to videos).
- Parallel Execution Models: Single program - multiple data (SPMD).
The time complexity for solving a linear system using RBSOR is O(Mn2) where M is the number of (outer) iterations and n2 is the 2D matrix (corresponding to images) size.
The original code is written in C (only for a pair of images) and our implementation is in C as well. For processing videos, we wrote bash scripts. We implemented multiple parallelizations we learnt in this class and compared their performance. To be more specific, we tried OpenMP, MPI, OpenACC and MPI+OpenMP for DeepFlow applied to 2 images and we tried the same methods and MapReduce+OpenMP (that's because OpenMP is the best for 2 images) for DeepFlow applied to video.
Parallelization Implementation and Overhead Analysis
Parallelization is based on RBSOR algorithm introduced above. The original SOR algorithm is not parallelizable.
OpenMP
As we said, in each iteration of RBSOR the elements could be processed independently, thus the OpenMP parallization is fairly straight forward. We simply wrap the the for loop with appropriate pragmas. We know clearly that each iteration needs strictly same amount of work so the OpenMP scheduling policy should be static.
The OpenMP implementation mainly has overhead on thread synchronization. The process needs to join the threads for each iteration thus making many system calls. There are also some overhead for creating and terminating the threads.
The theoretical speedup ignoring overhead is 1/(0.22+0.78/N) where N is number of threads. The actual speedup should be less because of the overhead we explained above. This theoretical speedup is also true for other methods working on 2 consecutive images.
OpenACC
Similar to OpenMP, we simply use pragmas to tell the compiler that the loops are independent within each iteration. In addition, we make sure data is only copied to GPU once, and copied out after the last iteration.
Since PGCC does not support SSE instructions (v4sf type), we also rewrote all related code, which introduces a lot of overheads.
The OpenACC overhead is mainly on the drop of SSE optimization (with SSE, CPU can calculate multiple data together) on the code running at CPU. With future release of pgcc, this overhead can be eliminated if SSE is supported. Data copy between CPU and GPU is also the overhead although we make sure in each linear system solver the data is only copied once. This is because we will solve around 300 linear systems.
MPI
We also implement distributed-memory parallelization by MPI. Since each process will only update a part of the data, we have to design how they communicate.
RBSOR can be viewed as doing update on a matrix. We implement MPI as master-worker structure. In master process, we split the matrix by row into n approximately equal blocks, where n is the number of avaiable worker process so that data we pass is continuously distributed, which is more convenient for worker processes to load and manipulate. And then we pass each block to its corresponding worker process, where we actually do our main computation. In each worker process, regular RBSOR algorithm is applied for smaller matrix blocks, and after we finish our calculation, we pass the results (which are also smaller matrix blocks) back to master process for the next iteration.
The message exchange is not trivial since we need to deal with the top row and bottom row in each split. We use a similar method (ghost cell) as in assignment and each worker process will receive additional rows (from neighbor process) that it won't update. Since RBSOR split the whole matrix into odd cells and even cells, the woker process also needs to know the parity of the first cell in its received block.
MPI has huge overhead on message exchange although we make sure rows not at the edge are only exchanged once after the last iteration. The reason is that the linear solver will be called around 300 times and there's message (ghost rows) exchanges anyway in each iteration.
MPI+OpenMP
This is just a combination of MPI and OpenMP, and easy to implement. MPI still requires us to do RBSOR in each worker node, where OpenMP can shine.
MapReduce + OpenMP
We choose Hadoop Streaming as our platform for MapReduce. In our task, the map task is calling the binary executable of DeepFlow (RBSOR OpenMP implementation) on each individual pairs of consecutive image files along with the correpsonding .match file to generate .flo files. The reduce task is an identity function (we can simply set mapred.reduce.tasks=0). By default, Hadoop streaming only supports streaming data as input and output. It is hard to properly format the image files and .match files as streaming input.
Our solution is to make use of the Hadoop File System (HDFS). We upload all the input files as well as the binary executable to the HDFS through the master node. The map task at each slave node works as follows:
- It downloads binary executable file to the local machine.
- The streaming data is the name of the input files used for computation. The slave node downloads the required input files from HDFS to the local machine.
- Each slave node calls the binary executable on the input files to compute .flo files locally.
- The local machine uploads the resulting .flo file to HDFS.
- We get the final output from HDFS at master node.
In addition, to increase the throughput, we generate the forward and backward flows for a pair of frames simultaneously on a worker node.
The overhead of this method is mainly on HDFS download and upload (which is quite slow to be honest). The MapReduce scheduling sometimes doesn't evenly distribute the work and it also generates the overhead.
Code Base
We made a list below for the code we wrote (i.e. not from original DeepFlow).
- serial Jacobi: solver
- serial RBSOR: solver
- OpenMP Jacobi: solver
- OpenMP RBSOR: solver
- OpenACC Jacobi: solver
- OpenACC RBSOR: solver
- MPI RBSOR: solver
- MPI+OpenMP RBSOR: solver
- MapReduce+OpenMP: MapReduce code
- Tool to make slow motion video based on DeepFlow: flo2svflow
- Bash script to generate DeepMatch and DeepFlow for videos: deepmatching-video.sh, video_flow.sh
Our GitHub repository is here